
Improving the Performance of Linear-Scaling BigDFT for ARCHER2 and Beyond
ARCHER2-eCSE07-02
PI: Dr Laura E Ratcliff (University of Bristol)
Technical staff: Dr Arno Proeme (EPCC, University of Edinburgh)
Subject Area:
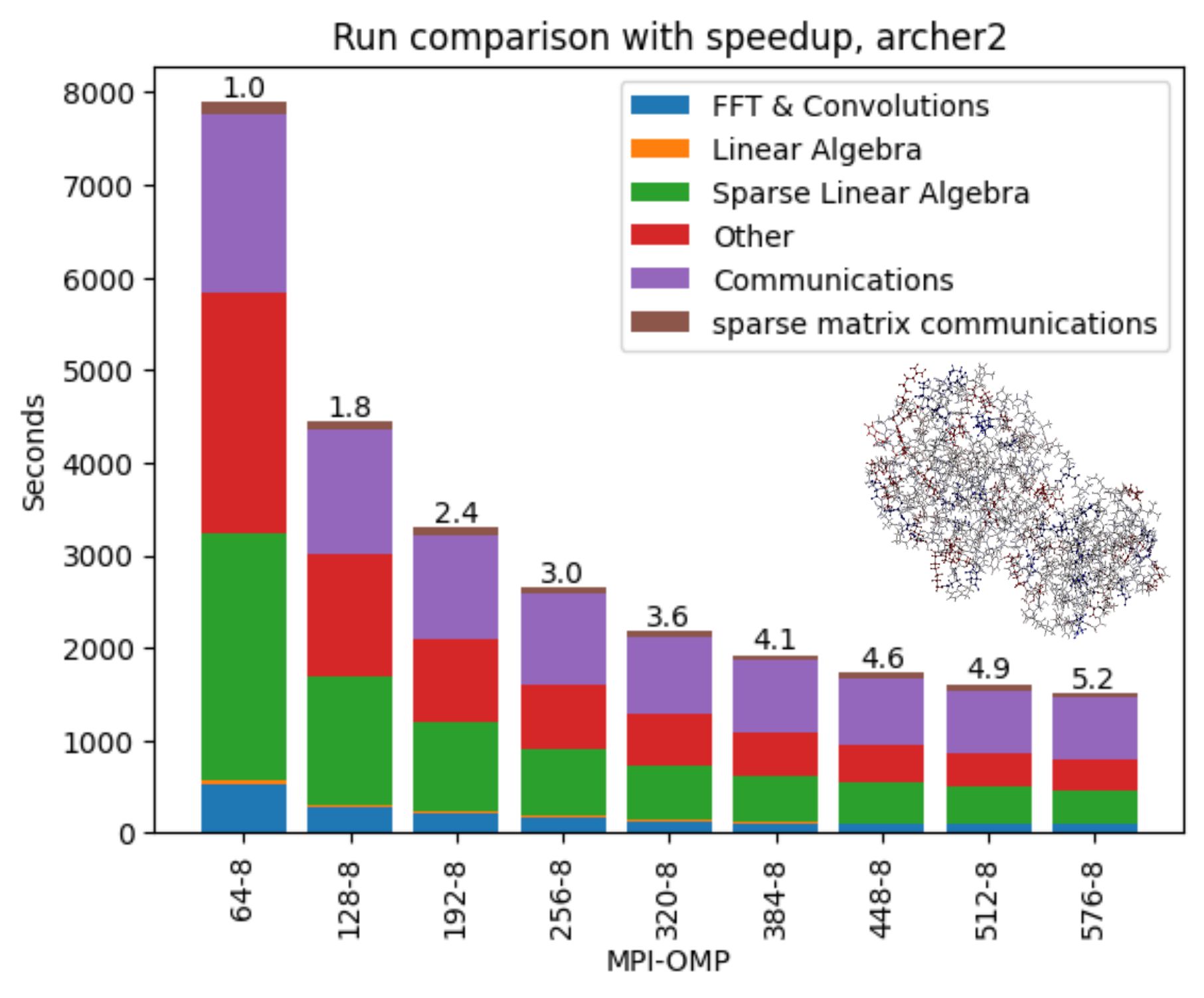
Parallel performance and timing breakdowns on ARCHER2 for linear-scaling BigDFT calculations of the SARS-CoV-2 main protease monomer, for which the structure is shown in the inset.
BigDFT [1] is a wavelet-based density functional theory (DFT) code, which takes advantage of the distinct properties of wavelet basis sets to efficiently simulate large and inhomogeneous systems, particularly in the linear-scaling (LS) version of the code, which can treat tens of thousands of atoms. The ability to simulate such large systems from first principles facilitates a range of applications, including for example understanding disorder and environmental effects in supramolecular materials typical of organic light emitting diodes, or in biological applications, where the fragment functionality in BigDFT can be used to form a network-based analysis of e.g. interactions in proteins. Thus BigDFT has the potential to offer insights into a diverse range of problems, from improving our understanding of materials for technological applications to applications in biology, like enzyme-based detoxification and comparing different SARS-CoV-2 mutations.
A key aim of this project was to improve the stability of LS-BigDFT on ARCHER2, which suffered unpredictable stability issues at the start of the project, e.g. hanging, which were attributed to the use of one-sided MPI communications. To this end, a number of bug fixes and other improvements, e.g to load balancing, were made to the one-sided MPI implementation, and collectively have led to significant improvements, enabling calculations to be performed for a range of system sizes (recent tests have gone up to around 5000 atoms) and node counts, which was not possible before the start of this project. All of these changes have been implemented in the latest release of BigDFT, and are therefore available to all users.
Several approaches prototyping implementation of two-sided communications within the communication of the potential were attempted, but doing so whilst making minimal changes to the existing code structure and working with existing communications infrastructure proved challenging. Nonetheless this generated insights that suggest a route for potential future implementation of two-sided communications.
Systematic scaling analysis was performed for a range of production-relevant target systems covering linear scaling and cubic scaling algorithms in order to determine rules of thumb for what choices of hybrid MPI+OpenMP parallel execution give optimal performance. As well as providing insights into fundamental aspects of BigDFT parallel performance these results should be especially useful in aiding users of BigDFT on ARCHER2 make best use of the machine.
Profiling was done to generate understanding of the bottlenecks underlying observed parallel performance trends, including the interplay between MPI and OpenMP parallelism and their respective bottlenecks, and the potential for improvement of OpenMP performance. BigDFT’s use of MPI and distribution of work across ranks was found to be the primary bottleneck to more highly performant scaling, with the existing OpenMP implementation already able to alleviate this somewhat through a reduction in the total number of ranks when running at a given scale.
[1] Flexibilities of Wavelets as a Computational Basis Set for Large-Scale Electronic Structure Calculations, L. E. Ratcliff, W. Dawson, G. Fisicaro, D. Caliste, S. Mohr, A. Degomme, B. Videau, V. Cristiglio, M. Stella, M. D’Alessandro, S. Goedecker, T. Nakajima, T. Deutsch and L. Genovese, J. Chem. Phys., 152, 194110 (2020)
Information about the code
BigDFT can be obtained from GitLab. The code includes a directory called rcfiles, which contains various configuration files, including for ARCHER2, which is periodically updated as needed. The rcfile also contains the modules to be loaded as commented lines at the top of the file. Once these modules have been loaded, BigDFT can be compiled by creating a build directory within the cloned bigdft-suite folder, then invoking the installer from within the build directory using the command
python3 ../Installer.py -f archer2.rc build
This will build BigDFT using the archer2 rcfile from the rcfiles directory. `