
Ten Tips for using HPC
By Clair Barrass EPCC, Andy Turner EPCC on November 28, 2023
Tags:
Working with HPC can be exciting, innovative and rewarding. But it can also be complex, frustrating and challenging.
Andy Turner is EPCC’s CSE Architect, he works with RSEs, UK HPC-SIG, DiRAC, The Carpentries and various user communities to share and improve HPC epertise.
We asked Andy for his Top 10 Tips for using HPC, to help make your HPC experience smooth and successful.
1. Don’t struggle alone
Researchers are good at solving problems… but this can lead to a tendency to not ask for help soon enough
Where can you find support?
Service Desk
Most HPC services have a service desk staffed by experts who are there to help you.
If something is not working as you expect: contact them
Remember to include:
- A description of the problem and/or the error messages you are seeing
- The job ID and submission script if it is a problem with the job
Research Software Engineers
There are many RSE groups around the UK that can provide advice and support.
They often have a broad range of experience and can help with general advice as well as specific support.
2. Learn an in-terminal text editor
Even if you do not use for the majority of your job setup it will stand you in good stead
Options:
- vim: can be tricky to learn but very powerful and available everywhere
- emacs: more intuitive to use than vim and almost always available
- nano: simple to use but less powerful, not always available
Some editors also support editing remote files over SSH, e.g. Visual Studio Code

See also “The Editor War”
3. Submit test jobs before scaling up
It is easy to waste a lot of resources when jobs do not behave as they should, not to mention the frustration of having to wait in the queue for days, only for the job to fail after 10s due to a typo!
Most HPC systems have a short/test queue that you can use for for testing, with fast turnaround
This is particularly important for more complex job scripts
Other scaling up issues you may hit:
- IO model becomes a problem: 1 CP2K jobs writing data works fine, 5,000 CP2K jobs writing data becomes a problem
- Organising and managing results and data becomes much more challenging:
- What if 1 run out of 5,000 fails? How do you identify it and understand what went wrong?
- How do you aggregate/analyse data?
4. Run some basic benchmarking
It is always tempting to just get on and get going with production runs… …but it is often useful to run some tests before you commit
Benchmarking:
- Optimises your use of your allocated resources
- Can also be useful to evaluate the most energy efficient approach if your system supports reporting on energy use
- Worth looking around to see if any advice already exists for the type of work you are doing
- Increases in importance if the architecture is different from things you have used previously
- Run some simple tests with restricted number of timesteps/iterations/SCF cycles
- For example, double node count, halve node count
- Be aware of calculation/model input parameters that can change performance
and test some values of these too:
- e.g. VASP: NCORE, KPAR; CASTEP: num_proc_in_cpu
5. Have a data management plan
- Understand your data:
- Which is critical and needs to be backed up in multiple places?
- Which can be kept on HPC system and which needs to be transferred off?
- Which can be regenerated easily?
- Do you need to archive files before transferring them?
- Does compression help or hinder?
- Compression can be CPU-intensive - may not make sense for your data
- How long will it take to transfer data?
- Can become CPU-bound due to encryption of transfers - significant speedup is often available by using faster encryption algorithms than the default (e.g. “scp -c aes128-ctr …”)
There is a data management guide for ARCHER2 users
6. Read the docs…
Most HPC facilities come with good documentation, it is worth browsing through this… … Not to memorise anything but to understand what is there to potentially look at in the future
Service desks will often point you to try advice from documentation before they investigate further
Documentation where the community can contribute is becoming more common, e.g.: ARCHER2 documentation
If you have looked through the docs and failed to find the topic you are looking for, let the service know so (e.g. by raising a github issue) so they can add it, or make finding it easier.
7. Take advantage of training courses
Lots of HPC, software, data analysis training material available
- ARCHER2
- The Carpentries
- HPC Carpentry
- CodeRefinery
- Local training at your institution
ARCHER2 Training
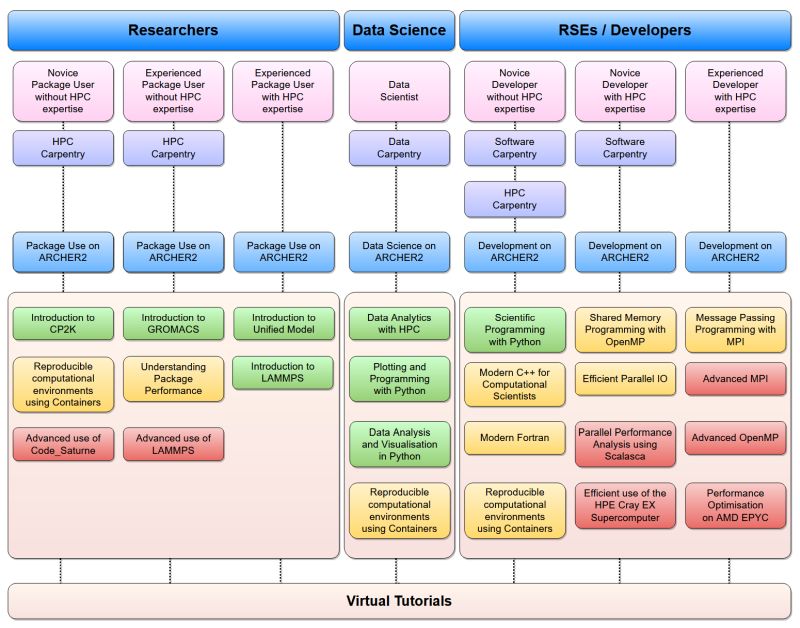
- Freely-available to all academics
- Wide range of courses at different levels
- Range of delivery methods
- In person
- Online taught
- Online self-service
- All previous course materials freely available online (with recordings) for self-study
8. Learn some more Linux command line
Modern Linux command line has lots of features that can be invaluable in streamlining research and data analysis
- Watch the webinar on Modern bash features
- Other useful command line tools:
- Combining bash and Python can lead to very powerful capabilities
9. Build on top of existing libraries/tools
Researchers are clever and creative and like building new things… But this is not usually the best approach when writing programs and scripts
- Almost always better to build on top of existing libraries and tools than develop your own
- If you are unsure what is already available, it is worth speaking to your local RSE group
10. Learn Pandas or R
Manipulating data is key to almost all research
- Pandas (Python) and/or R allows you to quickly perform sophisticated
analysis, plotting and transformations
- (and Pandas can often be parallelised using Dask)
- Easier to share and improve than worksheets
- Pandas is a fast, powerful, flexible and easy to use open source data analysis and manipulation tool, built on top of the Python programming
- R is a free software environment for statistical computing and graphics