
How to prepare a successful Technical Assessment
By Alexei Borissov EPCC on August 3, 2022
Tags:
There are a number of ways to get access to ARCHER2 (see https://www.archer2.ac.uk/support-access/access.html), and all of the ways that provide a significant amount of compute time require the completion of a Technical Assessment (TA). TAs are meant to ensure that it is technically feasible to run the applications users have in mind on ARCHER2, identifying suitable job sizes and data management practices, determining how much resource to allocate and whether there are any support requirements.
In this blog post we will discuss how to write a successful TA, the assessment process and the differences between the TAs required for different routes for ARCHER2 access.
Different types of TA
There are two different types of TAs. The first is for Pump-priming access, intended for granting relatively small amounts of time for porting and benchmarking codes on ARCHER2, and in preparation for larger grant applications to ARCHER2. The other is a general TA for grant access that requires more information about the performance of the codes used in the projects and allows for significantly larger compute time allocations. Links for the TA forms can be found at the url above. First we will cover the Pump-priming TA as it also covers many of the points for the general TA.
Pump Priming TA
The first two sections are fairly straightforward, requiring some contact information of the applicant(s) and listing previous experience with HPC services. If this is your first time using an HPC service or your first time using ARCHER2, there is an ARCHER2 driving test that will help you get familiar with using HPC systems (see https://www.archer2.ac.uk/training/driving-test.html).
Section 3 asks to fill in the software and requirements for compiling and running the application. Short descriptions of the codes and links to the source if possible are helpful. Software requirements including compilers and libraries required for running the code, and any tools (e.g. for post-processing) should be listed here also. Many of these are likely already installed on ARCHER2, so it can be worth having a look at (https://docs.archer2.ac.uk/research-software/ and https://docs.archer2.ac.uk/software-libraries/ ) to see if they are available.
This is also the place to mention whether there are any requirements for support to port or optimise your code to ARCHER2. This could involve, for example, help with installing dependencies, suggesting optimal parameters for submission scripts or Lustre IO configuration.
Support for more extensive code optimisation is available via regular eCSE calls.
Resources
Table 1: Example job breakdown table
| Job breakdown | Largest Job | Typical Job | Smallest Job |
|---|---|---|---|
| Number of nodes | 5 | 2 | 1 |
| Number of cores used per node (usually 128) | 128 | 128 | 128 |
| Wallclock time for each job (Max. 48h) | 24 | 48 | 12 |
| Number of jobs of this type | 5 | 10 | 10 |
| Total memory required. | 1280 | 512 | 256 |
Section 4 allows you to specify the resources requested. Here you can specify the job breakdown (see table in section 4.1) which will need to include the number of nodes requested, number of cores used per node, wallclock time per job, number of jobs and the total memory required for each job. This will need to be specified for the largest job you intend to run, the typical job and the smallest jobs. An example of this table being filled out is shown in table 1. Sometimes it might be beneficial to undersubscribe nodes (i.e. to use less than all of the cores intentionally), such as due to memory constraints when scaling performance of the code may suffer due to the high core count per node on ARCHER2. In these cases even though not all the cores are being used on the node it still gets charged at the full node CU rate.
In some instances it may be worthwhile to run on the high memory nodes which have 512GB per node (compared to 256GB on standard nodes), this could be noted here also. The CU calculator could be useful to compute the total amount of compute time requested.
This is also the section to specify storage requirements, consisting of backed up /home storage used for storing code and critical files, and a larger, high-performance, non-backed up /work filesystem used for running jobs and as temporary storage of resulting data.
Purpose
A brief description of the purpose of the application should be provided in section 5. This should include a description of the problem being addressed and justifications for the compute time and disk space requested. In the case of porting and benchmarking applications on ARCHER2 this would be a good place to explain what the representative test case for the problem being run is and the setup of any scaling experiments.
Data management
Finally in sections 6 and 7 a data management and transfer plan should be described. This involves specifying how much data over how many files will be read and produced by each job, how much of it will need to be transferred off ARCHER2, and how that will be done.
In general it is best to have as few files as reasonably possible for data storage, and this is especially true when transferring files. It is likely beneficial to compress multiple files into a single file using something like tar or zip before transferring them off ARCHER2 using rsync or scp. If transferring large amounts of data it is worth looking into whether it would be possible to use GridFTP. A discussion of these options and other things data related can be found at https://docs.archer2.ac.uk/user-guide/data.
This is all that is required for the pump-priming applications. We will now go over the extra details pertaining to TAs for other grant applications such as Access to HPC or Pioneer Projects. These all use the regular TA form.
TAs for Grants, Access to HPC and Pioneer Projects
Project Summary
The main difference in the first section is the addition of a project summary in which a high level description of what will be achieved using the computational resources provided. This should be brief as there will be space for the scientific case in the rest of the grant application.
Sections 2 and 3 have only minor differences that are self-explanatory, however the subsequent sections require much more detail in the general TA form.
Resources for multiple codes
The general structure of section 4 (i.e. total resource requests) is the same as for the pump-priming form, however if multiple codes will be used in the project it is essential that the job size mix table (in section 4.1) is filled out for each code.
Intended use cases
The intended use cases combined with the scaling information required in section 6 are necessary to make an evaluation whether it is practically feasible to run the required jobs.
Allocation periods
On ARCHER2 compute time is allocated in 6 month blocks so a breakdown of the time requested for the duration of the award should be provided in section 5. Any unused compute time allocation cannot be carried over once a 6 month allocation period is finished.
Code performance
In order to ascertain that the codes intended to be used are suitable for the job sizes requested evidence of code performance needs to be provided. This can be done in section 6.1. At the very least a table showing the runtime for a fixed problem size against the number of nodes should be provided.
| Number of nodes | Runtime (s) | Efficiency |
|---|---|---|
| 1 | 1000 | 1 |
| 2 | 545 | 0.92 |
| 4 | 296 | 0.84 |
| 8 | 177 | 0.71 |
| 16 | 95 | 0.66 |
| 32 | 110 | 0.28 |
This is known as strong scaling. The data should extend at least to the maximum number of cores that will be used in the jobs proposed in section 4 and for a problem that is similar to the ones that will be run on ARCHER2. In this case similar does not mean full science production runs for each number of nodes presented, but it does mean running a problem of similar computational complexity (e.g. using a similar number of particles, cells, degrees of freedom, etc. as would be used in production runs) for a period of time that will allow you to gather meaningful data and be able to extrapolate total runtime from. This should be done for each code that will be used in the project.
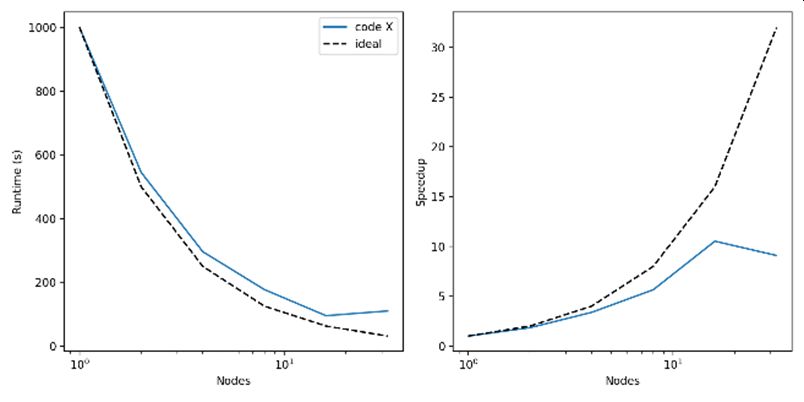
To help with evaluating the scaling data it would be good to present it as a plot, for example as speedup vs number of nodes (see figure above), also indicating ideal scaling performance (where speedup = number of nodes). The parallel efficiency (speedup/number of nodes) may also be presented as a plot or another column in the table. In general it is expected that the codes proposed to be used will be able to scale reasonably well to the job sizes requested, this does not mean that codes need to scale ideally, or even necessarily linearly, however there should not be a large drop off in performance or even anti-scaling for the job sizes requested.
Finally in some cases not all of this data may be available (for example if access to machines large enough to run the necessary jobs hasn’t been available, or the codes are in the final stages of development/optimisation), in which case justification for the anticipated performance should be presented using relevant work descriptions or references to similar work.
Job sizes
In section 6.2 a justification for the job sizes requested should be presented. This should generally take the form of a brief description of the problem setup (e.g. how many particles, cells, degrees of freedom, etc. are necessary for the problem being solved and how many timesteps are required for a single run), how much time each run is expected to take, and how many nodes will be required to do this. A description of the different runs required will be helpful here also. If it is planned to underpopulate nodes, for example for reason of memory footprint, this would be a good place to explain why.
Justification
To round out this section, in section 6.3 an explanation of why ARCHER2 is necessary for this work should be provided. This may be for any number of reasons, such as needing access to a large amount of compute time or being able to use more nodes will allow the work to be completed quicker than would be otherwise possible.
Summary
In summary, these TAs are necessary to determine whether codes will run well on ARCHER2. In the case of the pump-priming TA only basic information, such as job breakdowns and a data management plan are necessary.
For the general TA a detailed breakdown and justification of the jobs planned is required and evidence should be provided to show that all of the codes that will be used can perform well at the scale required.
The TA reviewer will be happy to work with you to help you present your proposal as clearly and effectively as possible.