
Investigating the performance of NAMD and NEMO on ARCHER2
By Eleanor Broadway EPCC on March 3, 2022
Tags:
In this blog, I will show results for the optimisation and tuning of NAMD and NEMO based on the ARCHER2 architecture. We looked at the placement of parallel processes and varying the runtime configurations to generalise optimisations for different architectures to guide users in their own performance tests.
We found that NAMD users should match the architecture of NUMA regions to find the optimal balance of thread and process parallelism. Reserving a thread per process improves the scalability on ARCHER2 by 12.5%. NEMO users can increase the efficiency of jobs by confining XIOS IO servers to NUMA regions and run larger simulations by reserving 75% of an ARCHER2 node without a performance detriment
Motivation
The HPC ecosystem throughout Europe is divided into different tiers: Tier-0 for European resources, Tier-1 for national, Tier-2 for regional and Tier-3 for local i.e., university clusters. ARCHER2 is the UK’s Tier-1 supercomputer and Cirrus, another supercomputer hosted at EPCC, is a Tier-2 regional service. As a very new service, ARCHER2 is an excellent example of modern supercomputing trends and representative of current and future Tier-0s with a many cores per node architecture. Because of this, we are perfectly placed to investigate the performance of codes on ARCHER2 and provide advice for users when moving their work from Tier-1 to Tier-0 machines.
How can we optimise codes based on the ARCHER2 many cores per node architecture? Do these optimisations also apply to Tier-0 machines? Based on these investigations, we can advise users on optimising for performance on Tier-0 machines based on ARCHER2.
Results
We assume that the reader is familiar with running NAMD or NEMO. Both are widely used on ARCHER2 so we hope that our optimisations will have a large impact on the community. We used standard benchmarks that optimise the computational performance however, both have limited application: typical production runs for NAMD have high memory requirements and NEMO performs significant I/O management.[1]
NAMD
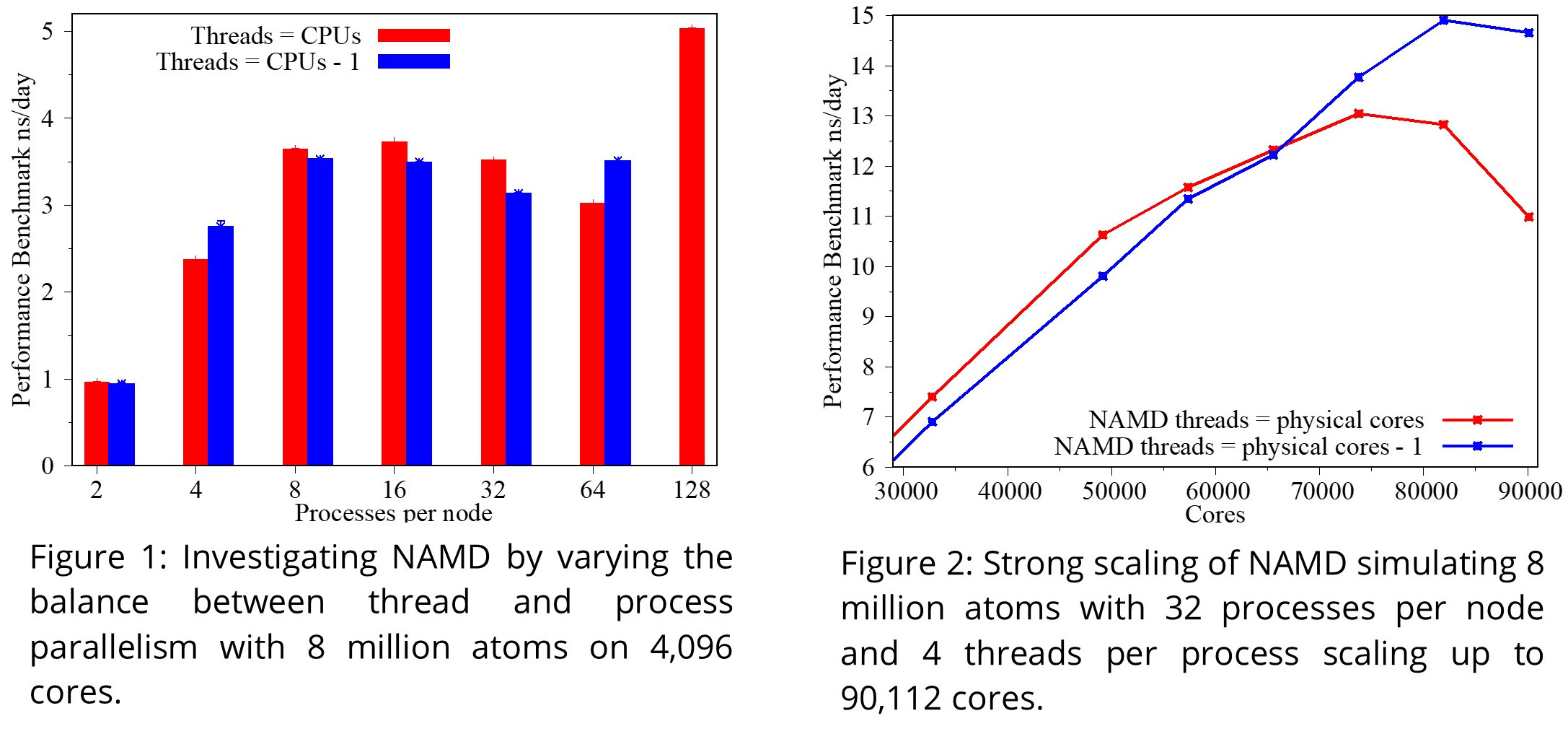
Figure 1 looks at the balance between thread and process parallelism on fully populated nodes. The best performance is clearly found with 128 processes per node and 1 thread per process i.e., without threaded parallelism. This is expected for our simplistic test case as adding threads will introduce additional communication overheads. However, most users will need to introduce threaded parallelism to reduce high memory requirements. Figure 1 shows that our optimal balance is 16 processes per node and 8 threads per process. This is significant as the pattern matches the ARCHER2 NUMA structure by mapping 2 process per region (8 NUMA regions per node with 16 cores per region). Users should copy the architecture of NUMA regions to find the optimal process placement.
The NAMD developers also recommend reserving a thread per process for communication to reduce communications between threads. Figure 2 shows that we improve scalability by 12.5% when reserving a thread per process as we delay the turning point by 8,192 cores. At lower core counts the performance benefits from the additional threads. Users should reserve a thread per process for communication to improve scalability.
NEMO
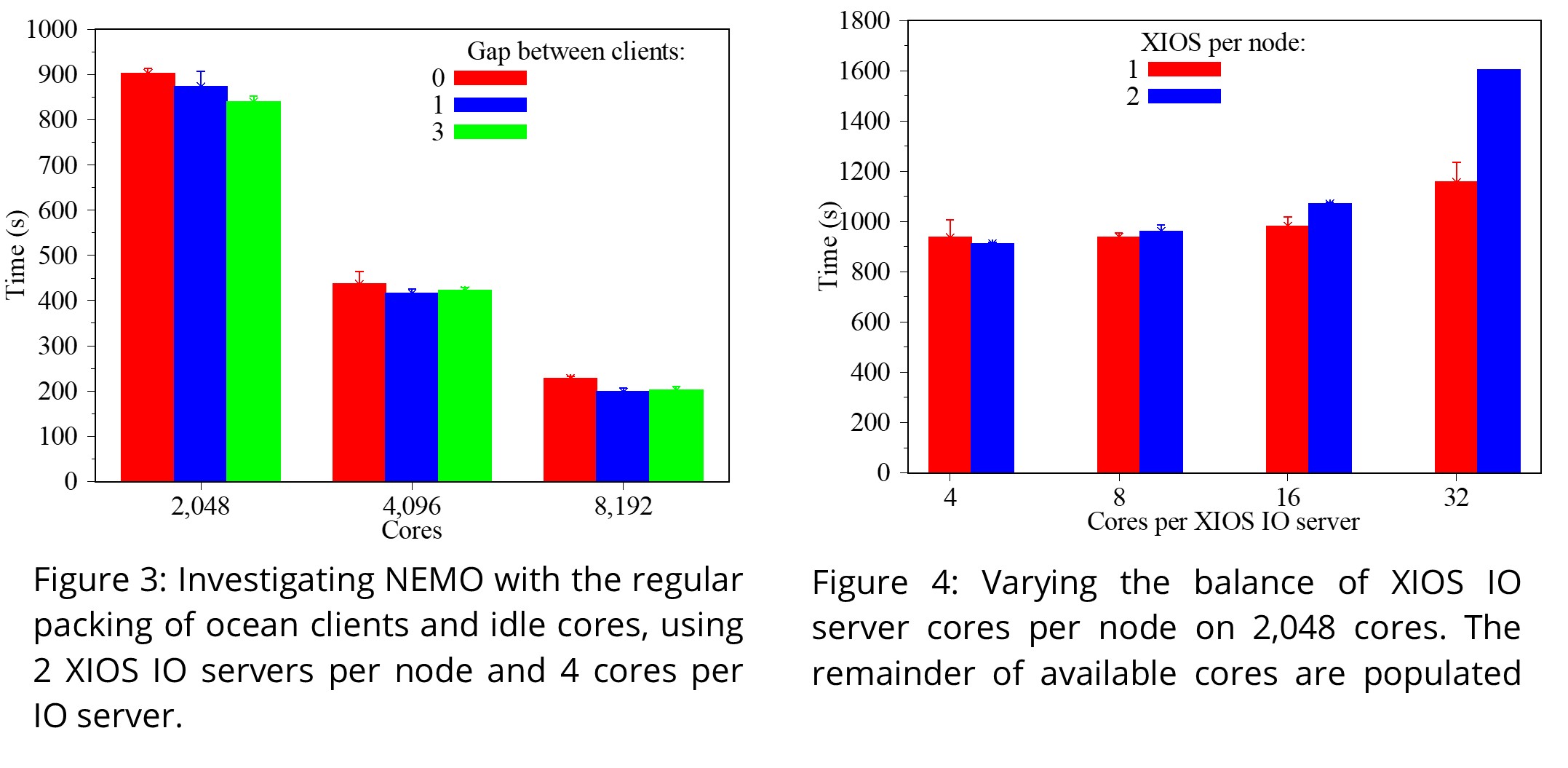
The NEMO developers recommend detached mode, where each process runs as an XIOS client with external XIOS IO-server processors, to manage the IO of large volumes of data. Figure 3 looks at the regular packing of ocean clients and 0, 1, or 3 idle cores between each client i.e., drastically under-populating the nodes. We can see that the performance of the computation, emphasised by our chosen test case, is not affected despite us only populating 25% of the nodes. This indicates that users can reserve large portions of the nodes for IO management without a performance detriment.
Figure 4 extends this investigation by increasing the number of XIOS IO server cores per node whilst fully populating the remainder of the node with ocean clients. We see limited variation in performance for 4, 8, 16 cores per XIOS server, as expected based on the limitations of the test case and results in figure 3. However, we do see that performance is affected when allocating cores outside of a single 16-core NUMA region. Users should confine XIOS IO servers to NUMA regions to benefit from the memory hierarchy.
Ongoing work
These optimisations are based on the Tier-1 machine ARCHER2 with a many cores per node architecture such that they may be applicable to current and future Tier-0 architectures. Further performance tests and tuning based on PRACE Tier-0 Joliot-Curie is ongoing at the time of this report written. Although the processor and node architecture is very similar to ARCHER2, the network is completely different.[2] We would expect to see the same qualitative effects in terms of performance, but the optimal parameter choices could be different.
[1] PRACE UEABS, Unified European Applications Benchmark Suite, https://repository.prace-ri.eu/git/UEABS/ueabs/-/tree/r2.2-dev/
[2] CEA, TGCC Joliot Curie hardware description http://www-hpc.cea.fr/en/complexe/tgcc-JoliotCurie.html