
ARCHER2 Job Priority
By Kieran Leach (EPCC) on July 15, 2021
Tags:
An HPC service such as ARCHER2 manages thousands of user-submitted jobs per day. A scheduler is used to accept, prioritise and run this work. In order to control how jobs are scheduled all schedulers have features for defining the manner in which work is prioritised.
On the ARCHER and ARCHER2 systems we organise jobs based on a number of factors. The first of these is assigned queue or QoS priority. Priority is typically either low, standard or high*
The vast majority of work falls into the standard priority band – this work should always run ahead of low priority work but behind high priority work. Low priority work is typically uncharged or charged at a reduced rate but will only run when there is no suitable standard or high priority work to run in its place. High priority is typically limited to specific use cases – COVID-19 research has been the primary use case of high priority capability on ARCHER2 to date.
The second factor considered in scheduling work is time – both the amount of time a job has been queueing for but also the length of a job. Finally, the size of a job will be taken into consideration - expressed as a node count or proportion of the whole system.
In this blog we will look at how job priority was calculated for the ARCHER service, how it is currently calculated for the pioneer ARCHER2 service and how we plan to calculate it for the main ARCHER2 service.
ARCHER
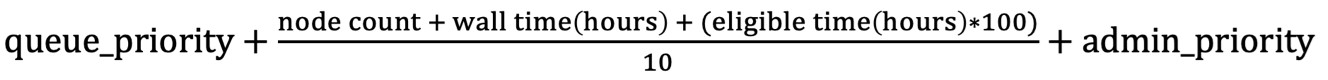
ARCHER used the PBS Pro scheduler which uses a formula defined within the scheduler’s configuration. Shown above is the formula used over the final years of the ARCHER service. In this formula only queue and admin priority are fully weighted – the other factors considered are divided by ten before being added to the queue priority and admin priority.
As discussed above the queue priority is set into bands of high, standard and low. Admin priority allows system managers to increase or decrease the priority of individual jobs however this facility was not actively used on the ARCHER service.
The other factors considered in this formula are node count, wall time – representing the planned length of a job - and eligible time, representing the length of time a job has been queueing. Node count is unsurprisingly the number of nodes requested by the job being submitted. Wall time is then included at a rate equivalent to one additional node per hour of wall time. Eligible time is then at a rate equivalent to one hundred additional nodes per hour.
Given that ARCHER had 4920 nodes the maximum benefit in priority terms that a large job could receive was around two days – that is to say that a newly submitted job attempting to use the full system would be considered equivalent in priority to a theoretical zero node job which had been submitted 49 hours ago.
The weighting given to eligible time was originally lower on the ARCHER service, with a much greater effective priority given to larger jobs. The original job sort formula applied no multiplier to eligible time meaning that each hour in the queue was equivalent to only one compute node. Even a moderately size job of 256 nodes would immediately be given priority over a ten day old theoretical zero node job – a job using half the system would be given priority over a hundred day old job.
As demand on ARCHER increased during 2016 wait times for some users became particularly long – the users in question being those with smaller jobs. After reviewing available options a multiplier was added to the eligible time – taking the equivalent node count per hour to ten. This was then increased so that the equivalent node count per hour reached 100, as above.
With this change in place wait times on the system became more acceptable – at a review the following year it was identified that all but 0.5% of jobs were running within three days and that 75% of jobs were waiting less than 6.5 hours to run.
ARCHER2 Pioneer System
The ARCHER2 pioneer system uses Slurm for scheduling rather than PBS Pro. Whilst PBS Pro calculates priority using an explicitly defined formula Slurm uses a variety of weightings and other variables provided to the scheduler. On the ARCHER2 pioneer system these are:
FairShareDampeningFactor = 1 PriorityDecayHalfLife = 28-0 PriorityCalcPeriod = 1
PriorityWeightQOS=10000 PriorityWeightAge=500 PriorityMaxAge = 14-0 PriorityWeightFairshare=300
These variables and weightings define the consideration of priority based QOS priority, job age and “fairshare” which we will discuss further below. In order to allow for an easier comparison this can be expressed as a formula in the same way as on ARCHER:
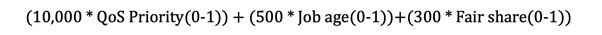
Each of the factors considered is calculated by Slurm as a number between zero and one – this is then multiplied by the weight assigned to the item. No priority is assigned for any factor for which no weight has been set.
The first factor, QoS priority, is equivalent to queue priority for ARCHER and is based upon the QoS a user has submitted to. The QoS priority is very heavily weighted (10,000) compared to other factors – for jobs in the high priority QoS this will result in a priority of 10,000, for the standard QoS a priority of 1,000 and for the low QoS a priority of 2.
The second factor used here is the age of a job – the length of time for which it has been queueing. A maximum age to be considered has been set which limits consideration at 14 days. Given the weighting of this factor at 500 priority would be assigned on a scale from 0 to 500 where a brand new job would be assigned zero and a job which was submitted 14 or more days ago would be assigned 500.
The final factor considered here is known as the fairshare factor. This is calculated based on the previously submitted and completed work of different groups on the system with groups and users who have run less work previously given priority. Consideration of work run is discounted at a rate with a half-life of 28 days - a piece of work run 28 days ago would have half the impact on the priority of a new job that a job submitted yesterday would.
As the fairshare factor is weighted at 300, previous work can be counted as the equivalent of up to 8 days of queuing time. With budgets in place on the ARCHER2 Pioneer System the fairshare factor is now considered excess to needs and we intend to remove this from consideration at an appropriate future maintenance.
As can be seen above job size is not considered in the ARCHER2 Pioneer System scheduling. This is considered appropriate given the reduced size of the system.
ARCHER2 Main System
As with the ARCHER2 Pioneer System the ARCHER2 Main System uses Slurm for scheduling. The weightings and other variables planned for calculating priority differ from the ARCHER2 Pioneer System however, as can be seen below.
PriorityWeightQOS=10000 PriorityWeightAge=500 PriorityMaxAge = 14-0 PriorityWeightJobSize=100
These variables and weightings define the consideration of priority based once again on QoS priority and age but now with the addition of job size and the removal of fair share. Once again to allow comparison we can express this as a formula:

Again each of the factors considered is calculated by Slurm as a number between zero and one – this is then multiplied by the weight assigned to the item. No priority is assigned for any factor for which no weight has been set.
The first two factors – QoS priority and age – operate in the same manner as they do on the ARCHER2 pioneer system. Priority between 2 and 10,000 is determined for QoS priority based on the QoS to which a job is submitted and priority between 0 and 500 is determined based on a job’s age up to 14 days.
The change between the ARCHER2 Pioneer System and the ARCHER2 Main System, in addition to the removal of a fairshare factor, is the inclusion of job size as a factor. Given the weighting at 100 priority will be assigned on a scale from 0 to 100 where 0 represents a (theoretical) 0 node job and 100 represents a full-system job.
Given that the maximum available priority for the size of a job is 100 and the maximum available priority for a job’s age is 500 for 14 days or more a job can gain up to three days worth of priority from its size – the advantage in hours and days at various sizes is shown below:
| Job size | Advantage over zero-size job |
|---|---|
| 512 | 6 hours |
| 1024 | 12 hours |
| 2048 | 1 day |
| 4096 | 2 days |
| 5860 | 3 days |
The intent in these settings is to broadly replicate the setup which was in place on the ARCHER system as this was considered to be effective and fair to users. The maximum advantage available to a job based on size differs somewhat but is broadly comparable – 67 hours for 5,860 nodes as compared to 49 hours for 4,920 nodes.
In the same way that we did for the ARCHER service we will monitor scheduling and engage with users to ensure that scheduling works for all users. Where necessary we will of course update the factors determining scheduling priority.
Hopefully you will now have a better idea of how your job is scheduled after submission. You can find more details about working with the scheduler on ARCHER2 in our documentation at https://docs.archer2.ac.uk/user-guide/scheduler.html including some helpful best practices. We will of course be updating the scheduler documentation as the service goes on.
We’re excited to be launching the ARCHER2 Main system and we can’t wait for you to be able to submit your work there!
*Jobs in Slurm are submitted via a Quality of Service which defines various limits and the priority applied. QoS along with partitions (specified groups of nodes) take on the role which queues do in other schedulers.)