
ARCHER2 MPI with OpenMP mini-app benchmarks
By Mark Bull (EPCC) on June 1, 2021
Tags:
Quite a few application codes running on ARCHER2 are implemented using both MPI and OpenMP. This introduces an extra parameter that determines performance on a given number of nodes - the number of OpenMP threads per MPI process. The optimum value depends on the application, but is also influenced by the complex memory hierarchy of the dual-socket AMD Rome nodes on ARCHER2.
Here’s some results from a handful of mini-app type benchmarks (miniAMR, HPCCG and CoMD).
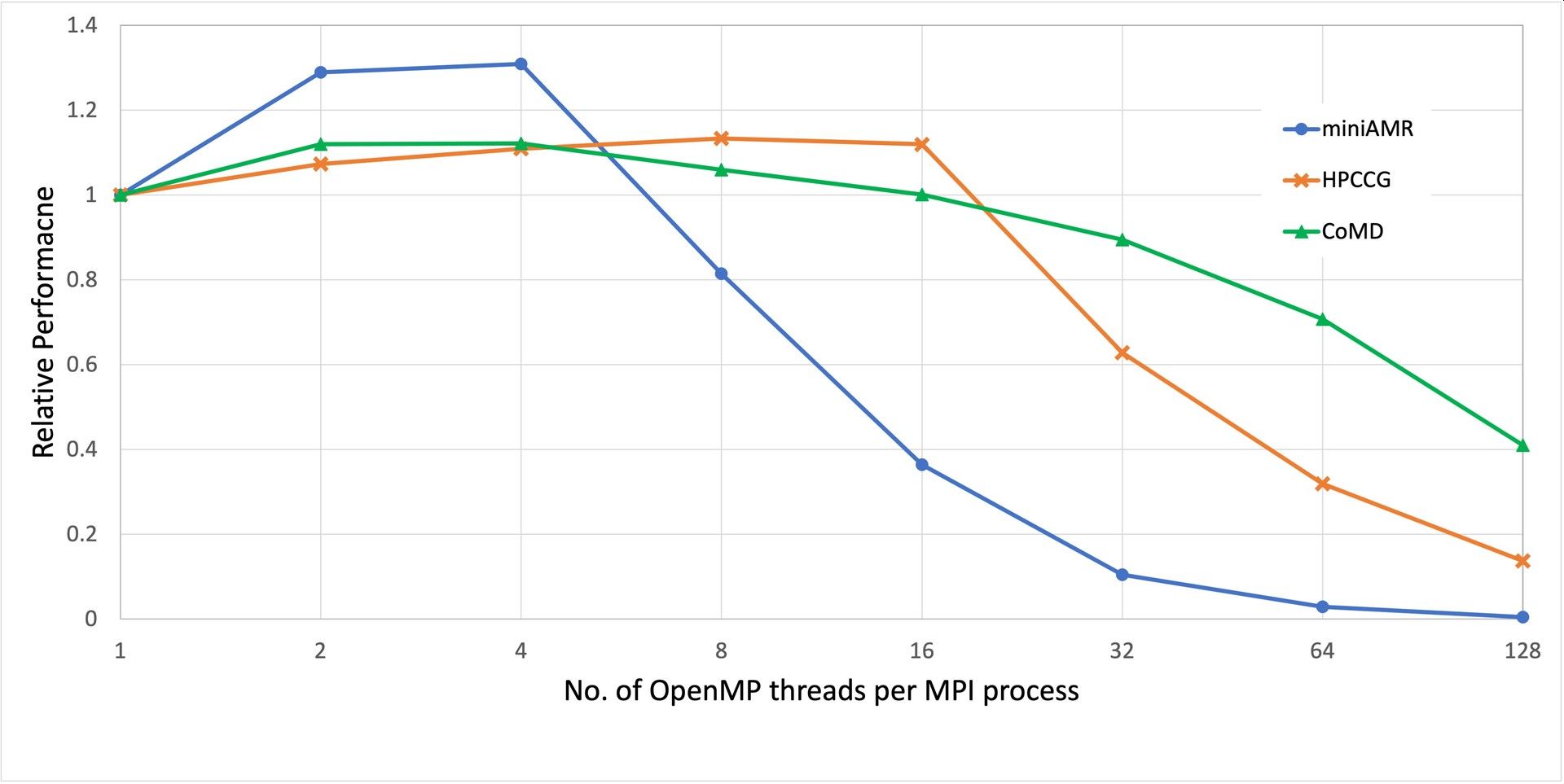
All runs are on 8 nodes (= 1024 cores) and use all the cores, without SMT. The y-axis is performance relative to 1 thread-per-process (so high is good), x-axis is the number of threads per process. The 3 curves are quite different, but best performance is at 4 or 8 threads per process, and more than 16 threads per process (i.e. going beyond a NUMA region) is bad for all 3 codes. For HPCCG and CoMD, going beyond 4 threads per process (i.e. beyond the groups of 4 cores that share Level 3 cache) does not have a major impact. For miniAMR, 8 threads per core is much worse than 4, but this is an irregular application where many different sources of overhead could be in play.